一、基本思路
- 预处理数据,将UCCA图转化为短语结构树的形式。
- 处理implicit节点
- 处理linkage node
- 处理remote边
- 处理discontinuity
- 调整label位置到non-terminal node上
- 用span parser训练(预测)
- 把短语结构树还原成UCCA图
二、预处理数据
下图统计了所有数据集的大小。但以下测试都是在英文的训练集和开发集上统计的。
| train | dev | test | total | |
|---|---|---|---|---|
| corpus | #sentence | #sentence | #sentence | #sentence |
| English-Wiki | 4113 | 514 | 515 | 5142 |
| English-20K | 0 | 0 | 492 | 492 |
| French-20K | 15 | 238 | 239 | 492 |
| German-20k | 5211 | 651 | 652 | 6514 |
1.处理implicit节点
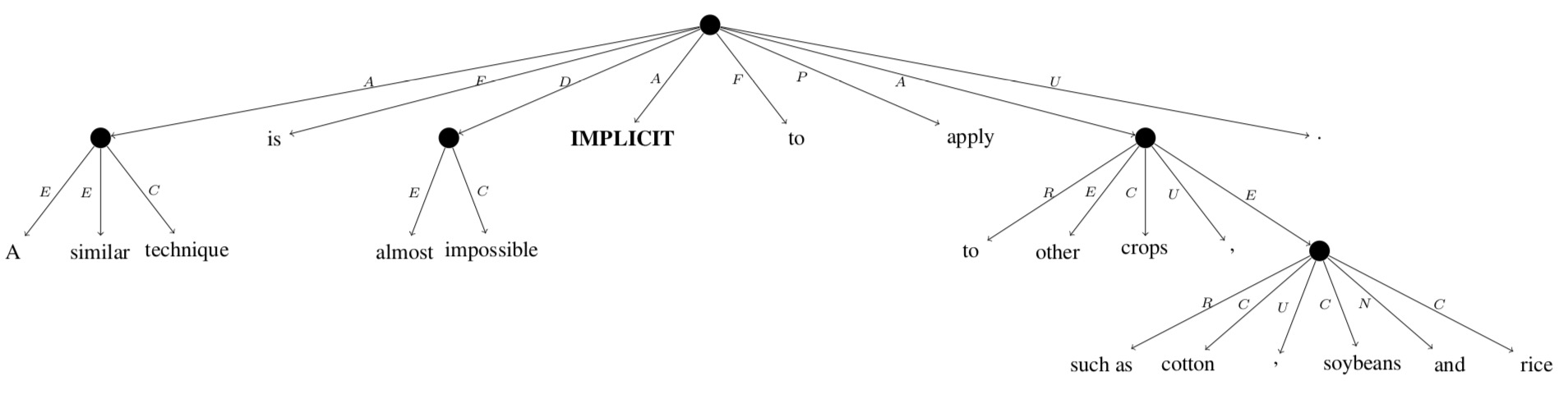
implicit节点是UCCA中的特殊节点,它没有对应的叶子,如下图所示。baseline模型中也没有提出有效的办法处理它,所以直接将其删除,不考虑。implicit数量待统计。
2.处理linkage node
linkage node也是baseline中一个尚未解决的问题。它类似root节点没有父亲,但它对应的span是句子的一部分。也就是说,一个句子可能会构成类似森林的结构,如下图。统计了训练集和开发集,发现共有3818个linkage node出现在了2544个句子中,对应的边应该更多,或许这就是论文中结果并不高的原因。暂时将所有linkage node以及它出去的边全部删去。
3.处理remote边
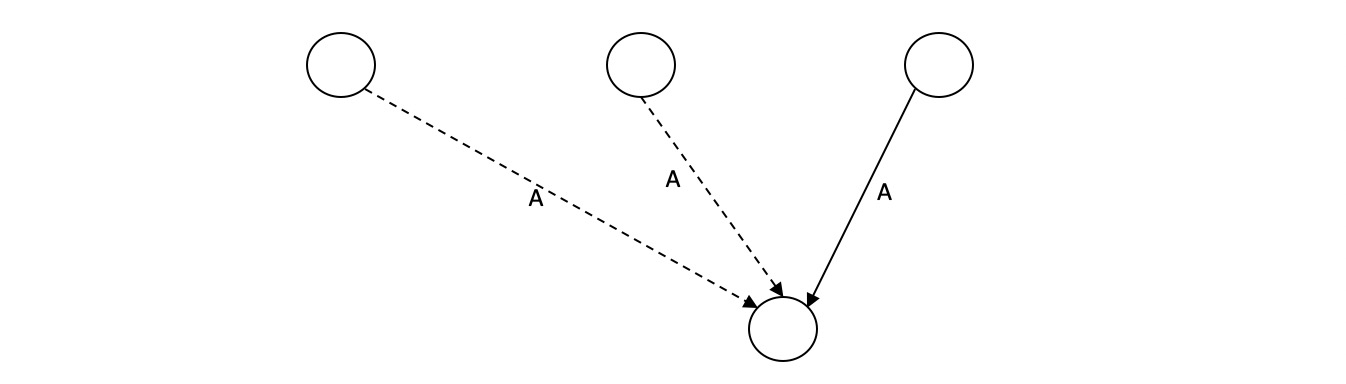
短语结构树要求每个节点只能有一个父亲,而UCCA允许一个节点有多个父亲,其中一个父亲经过primary edge(实边)指向它,其他父亲经过remote edge(虚边)指向它。为了消除remote edge,同时又能还原信息,采取扩展标签的方式。如下图所示,只要删除remote edge,同时在primary edge的标签上添加额外的信息,告知该边指向的节点还有其他remote edge指向它即可。简单起见,就在标签后面添加“-R”。
但是一个节点可以有多条remote edge指向它,仅仅添加“-R”似乎还不够。于是我统计了训练集和开发集(英文)的remote edge分布,如下图,其中第一行表示共有3626个节点只有1条remote edge指向它。根据分布,或许不必要考虑多条remote edge的情况。
| corpus | English-Wiki | |
|---|---|---|
| #remote edge | #node | proportion |
| 1 | 3626 | 83.0% |
| 2 | 596 | 13.6% |
| 3 | 104 | 2.4% |
| 4 | 31 | 0.7% |
| 5 | 6 | 0.1% |
| 6 | 2 | 0.1% |
| corpus | German-20K | |
|---|---|---|
| #remote edge | #node | proportion |
| 1 | 3546 | 85.7% |
| 2 | 464 | 11.2% |
| 3 | 93 | 2.2% |
| 4 | 16 | 0.4% |
| 5 | 10 | 0.2% |
| 6 | 5 | 0.1% |
| 7 | 2 | 0.1% |
| 9 | 1 | 0.1% |
remote node与primary父节点的位置关系如下图:
| corpus | English-Wiki | |
|---|---|---|
| remote node和primary父节点关系 | #node | proportion |
| 兄弟 | 1969 | 37.2% |
| 子孙 | 2398 | 45.3% |
| 父代 | 0 | 0% |
| 其它 | 929 | 17.5% |
| corpus | German-20K | |
|---|---|---|
| remote node和primary父节点关系 | #node | proportion |
| 兄弟 | 1498 | 30.4% |
| 子孙 | 2439 | 49.6% |
| 父代 | 1 | 0% |
| 其它 | 982 | 20.0% |
4.处理discontinuity
短语结构树要求每个non-terminal节点对应的叶子必须连续,而UCCA允许叶子不连续。判断一个节点的叶子是否不连续比较容易,共有939个node出现了discontinuity,分布在735个句子中,占比不是很大。我主要把这些node分成两类。
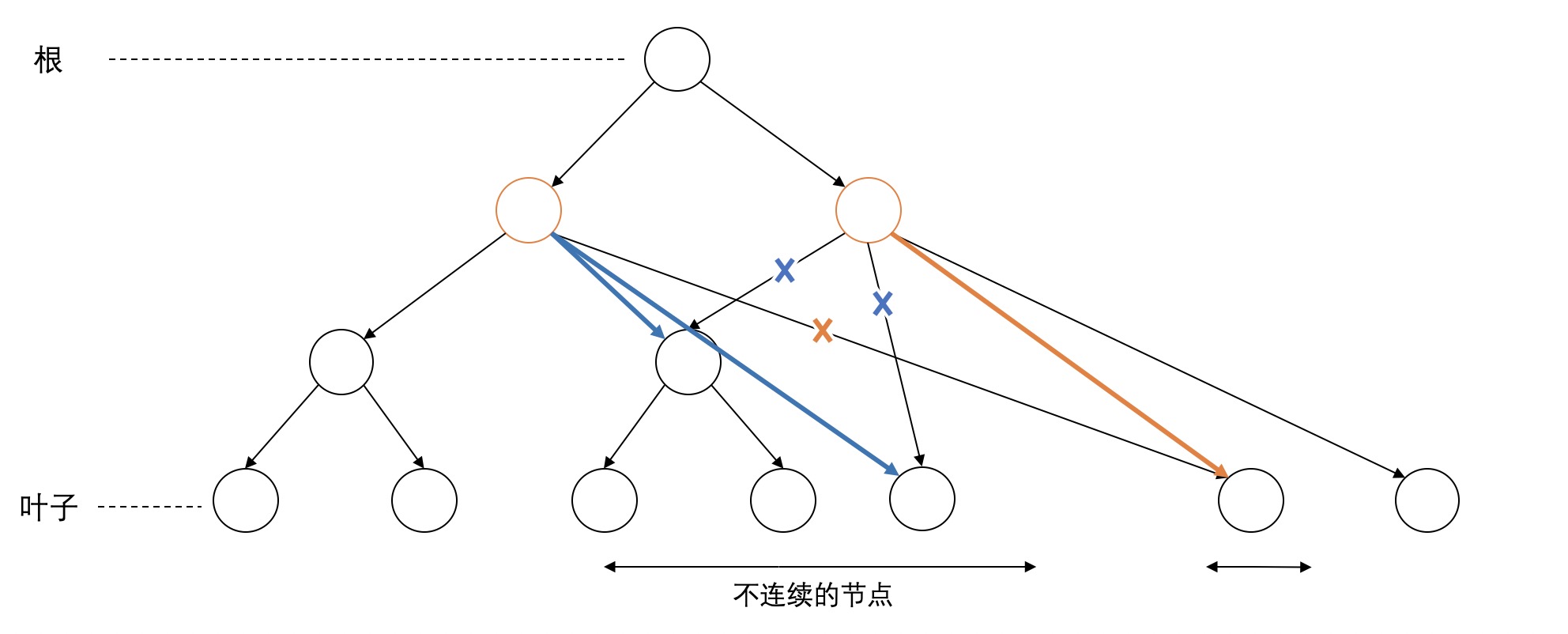
第一类是node之间没有交叉的discontinuity,如下图所示。不管如何,这种情况可以用两种方法调整。第一种策略是向下移动,这种策略定死了span的左右范围,把范围里的不连续节点移到该范围内。如图中黄色标记所示。第二种策略是向上移动,如图中蓝色标记所示,显然在该例子中向上移动的代价要小一些。
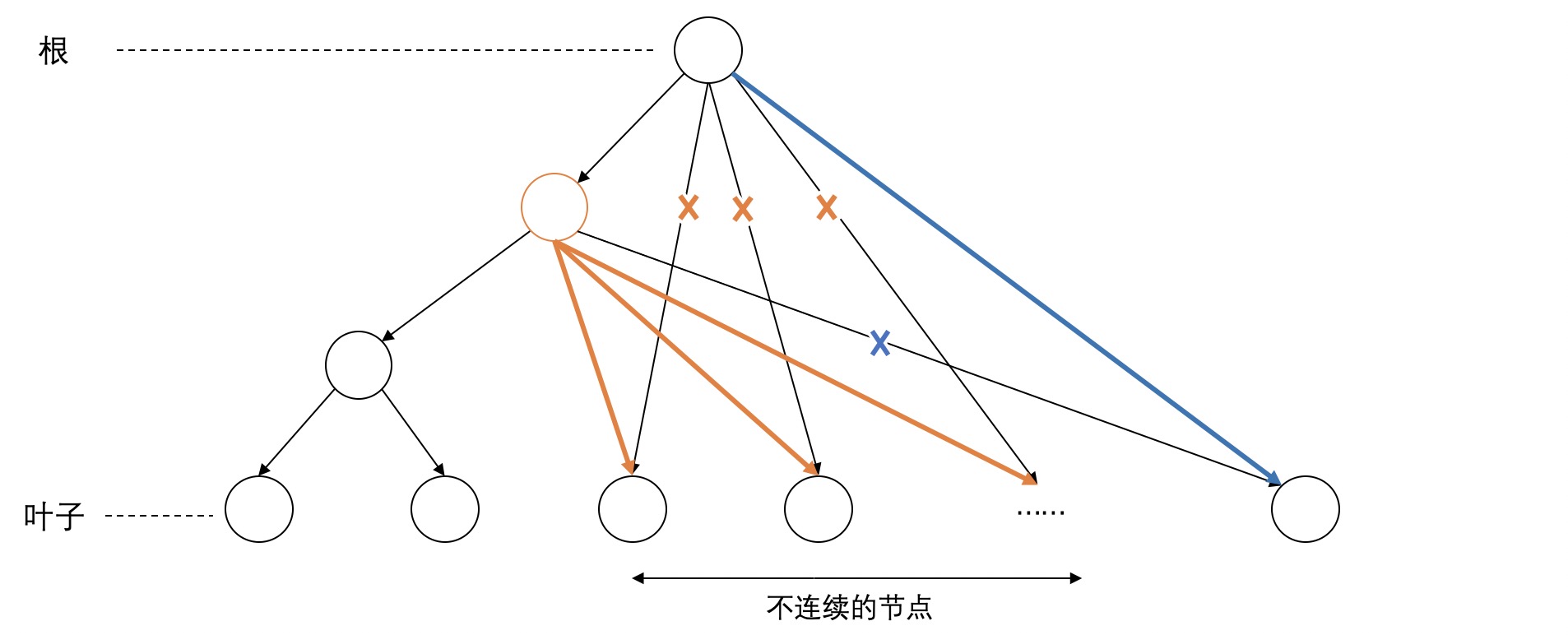
再来看下面一个例子,如果采用向下移动的策略,只要修改一条边,但有一个子树移动了位置。如果采用向上移动的策略则要移动右边所有的边,似乎这样代价比较大。事实上,我目测数据中这种情况最多,span中不连续的叶子只占一小片,向下移动只要动这一小片叶子即可,而向上移动要把右边所有的叶子都调整位置,也可能会移动右边的子树,所以大部分情况不是很好。
同样下面的例子也可以用向上和向下两个策略来解决。总之,只要一个句子中只有一个span出现不连续,或者多个不连续的span彼此不交叉,都可以用这两种方法解决。到时候只要选择代价较小的方法即可。目前向下移动已经实现完。
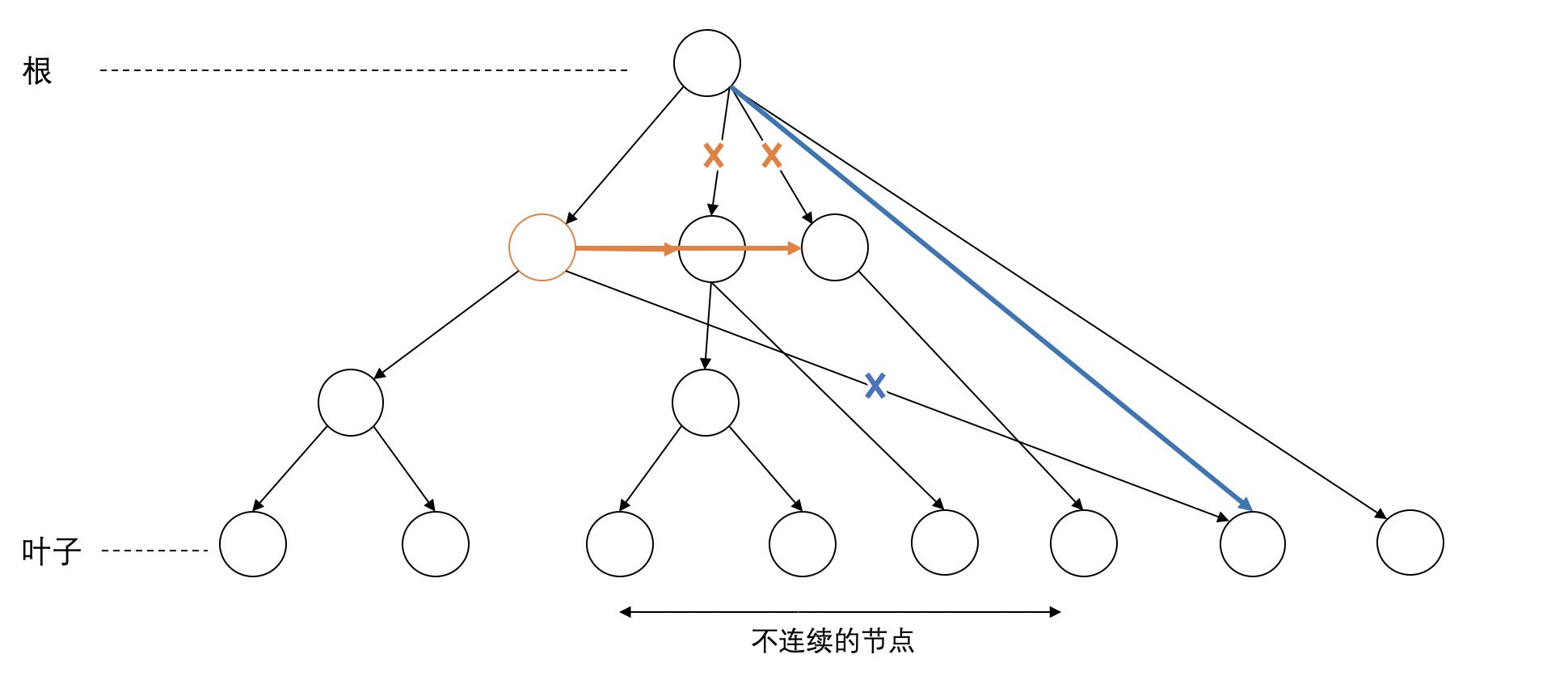
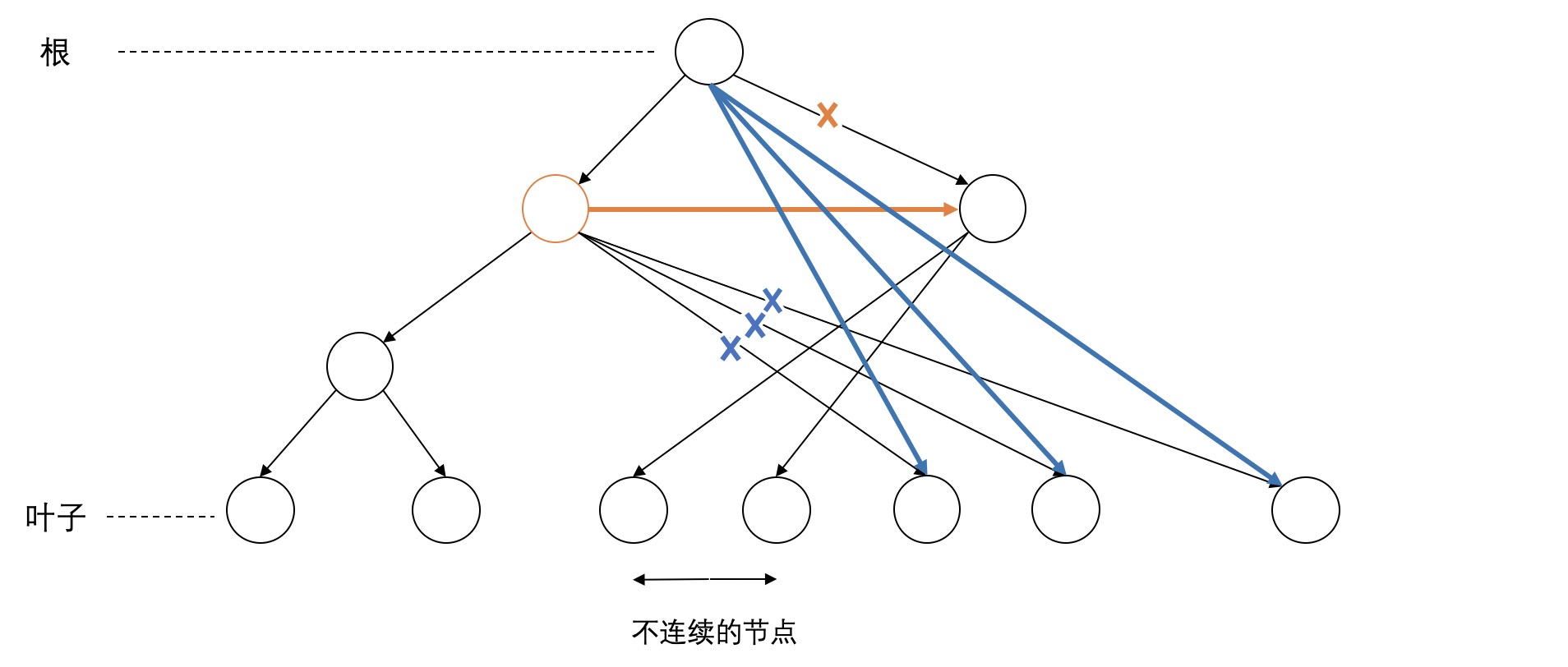
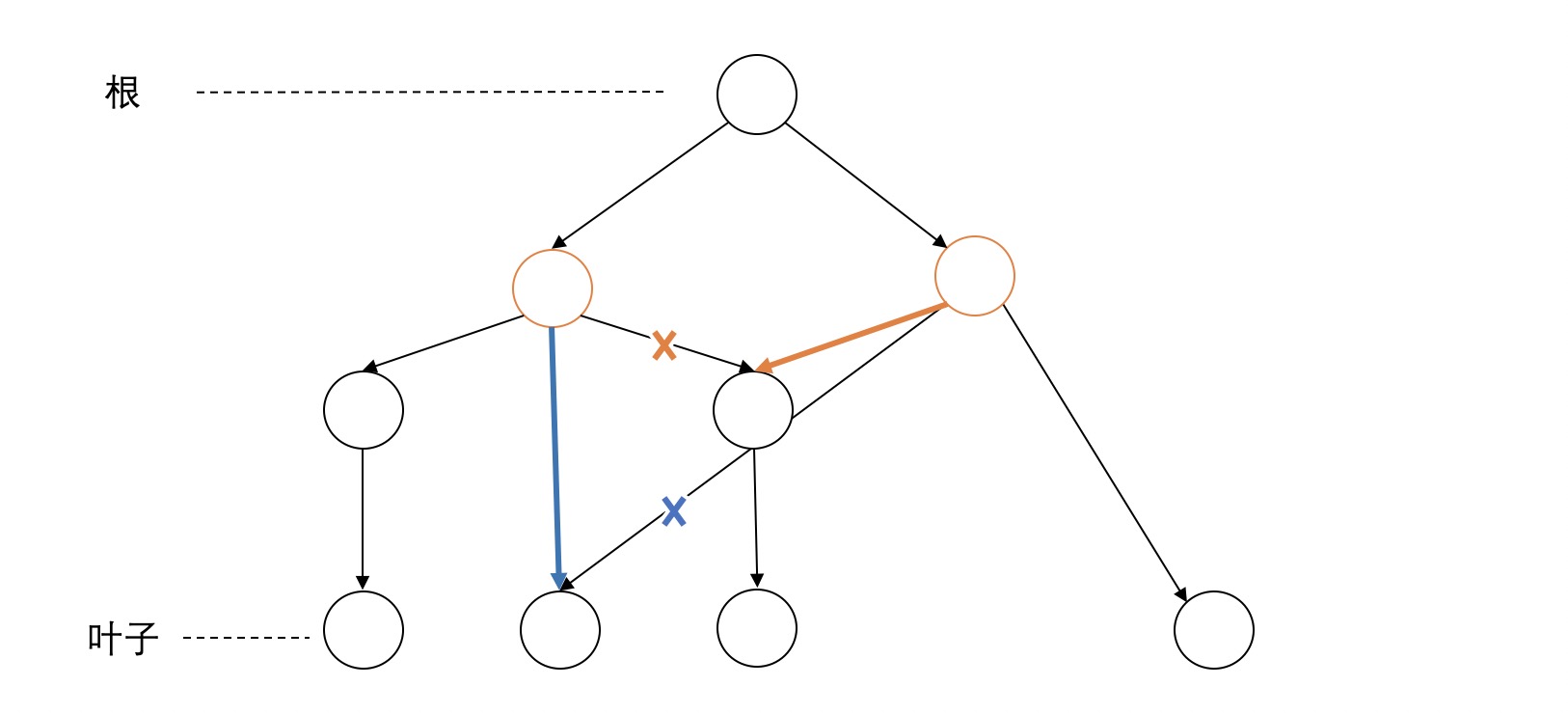
第二类是node之间出现了交叉的discontinuity,统计了共有125对交叉的node。如下图,有两块不连续的span(图中标红的node的span)有交叉。这种情况比较简单,似乎也可以用向上和向下移动的方法解决,如图中黄色和蓝色标记。目测这种情况占大多数。
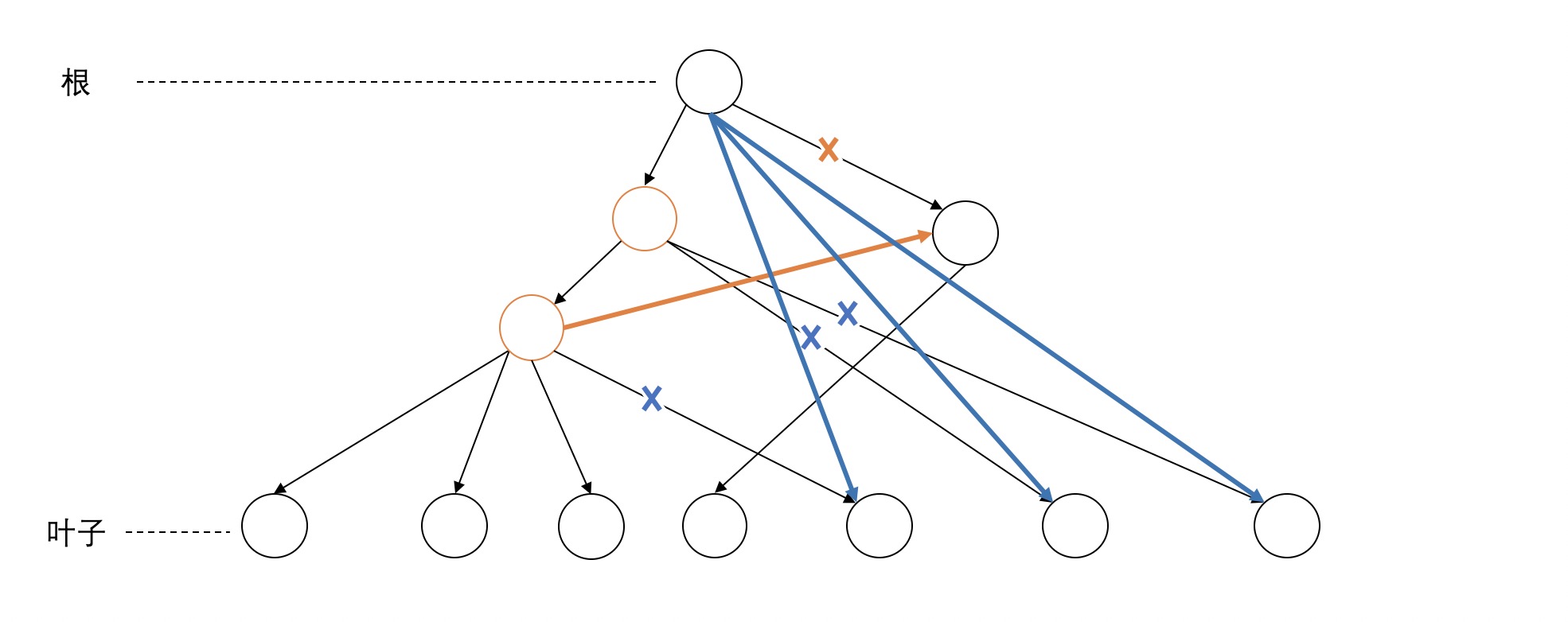
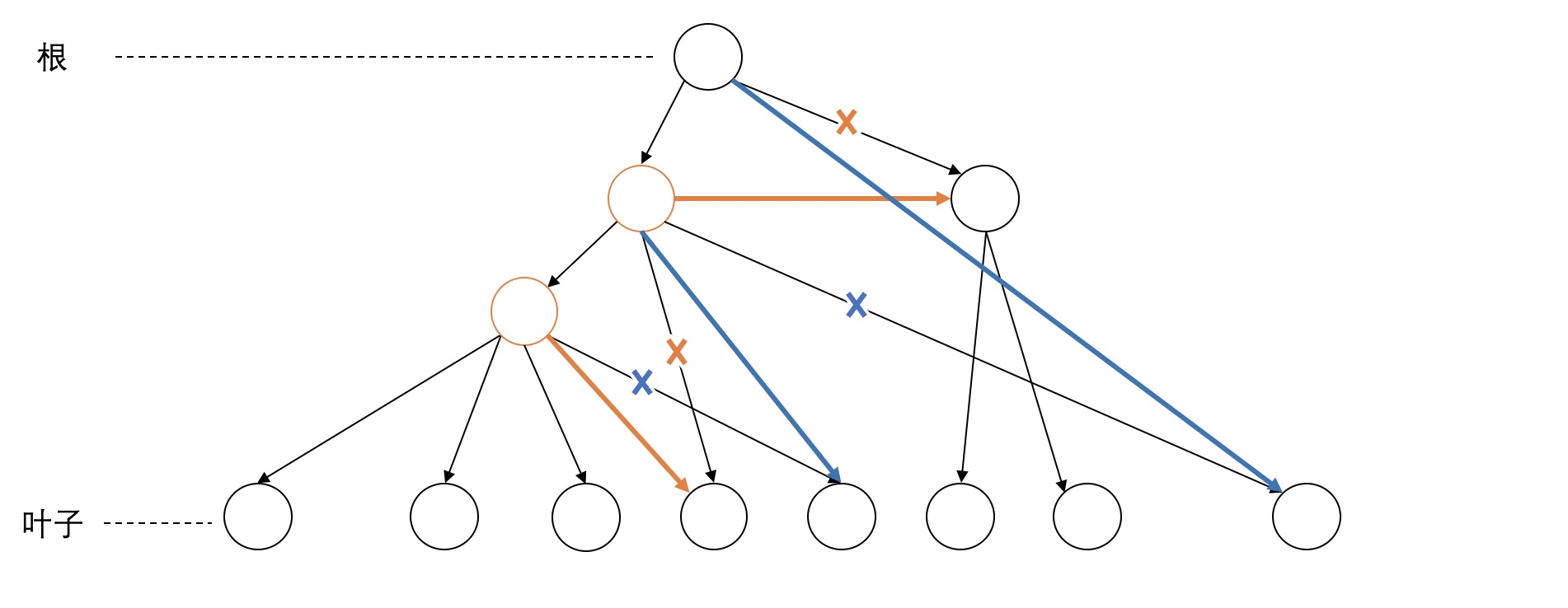
但下面这个例子比较复杂,从图中来看可以找到一个比较好的移动方法,但是光向上或者向下移动无法解决两个node的不连续。同样有两种策略来解决。一种是向右移动,如图中黄色标记所示,把右边不连续的节点移到右边的span中。与之对应的就是向左移动,如图中蓝色标记所示。这两种方法都可以看成是先向上移动,再向下移动。
经过试验,英文数据集中所有的discontinuity都可以归类到上述类别中,没有更加复杂的情况了,可以用向上或者向下移动变成连续的树。统计的操作情况如下,只用向下和向左操作。
| corpus | English-Wiki | ||||
|---|---|---|---|---|---|
| move | train | dev | test | total | proportion |
| down1 | 1460 | 149 | # | 1609 | 91.3% |
| down2 | 96 | 19 | # | 115 | 6.5% |
| down3 | 21 | 0 | # | 21 | 1.2% |
| left1 | 16 | 2 | # | 18 | 1.0% |
| corpus | French-20K | ||||
|---|---|---|---|---|---|
| move | train | dev | test | total | proportion |
| down1 | 8 | 156 | # | 164 | 60.7% |
| down2 | 96 | 3 | # | 99 | 36.7% |
| left1 | 0 | 4 | # | 4 | 1.5% |
| left2 | 0 | 3 | # | 3 | 1.1% |
| corpus | German-20K | ||||
|---|---|---|---|---|---|
| move | train | dev | test | total | proportion |
| down1 | 7268 | 673 | # | 7941 | 83.6% |
| down2 | 1068 | 119 | # | 1187 | 12.5% |
| down3 | 109 | 0 | # | 109 | 1.1% |
| down4 | 10 | 0 | # | 10 | 0.1% |
| down5 | 1 | 0 | # | 1 | 0% |
| down6 | 6 | 0 | # | 6 | 0% |
| left1 | 103 | 2 | # | 105 | 1.1% |
| left2 | 94 | 3 | # | 97 | 1.0% |
| left3 | 34 | 0 | # | 34 | 0.3% |
| left4 | 6 | 0 | # | 6 | 0% |
三、训练span parser
经过进一步的处理,把数据处理成结构树的形式后,我们使用minimal span parser(github链接)来训练。数据格式如下图所示,扩展的标签只有-remote,-down,-left,也就是说我们只考虑只有一条remote边,只向下走一步,只向左走一步。需要注意的是数据中会有 ‘(’ 和 ‘)’ 标点导致代码读取数据出错,统一替换成了 ‘{‘ 和 ‘}’。
(TOP (ROOT (H (A (PROPN Hammond)) (P (VERB defended)) (A (PROPN Dylan)) (D (ADV vigorously)) (U (PUNCT .)))))
经过初次实验,span parser在dev上的准确率只有79%左右。如果再经过多个步骤还原为UCCA图进行评价,结果肯定会更低。感觉还有提升的空间,因为span parser只用了pos特征,而baseline用了pos、dependency、entity等等大量的特征。
四、还原为UCCA gragh
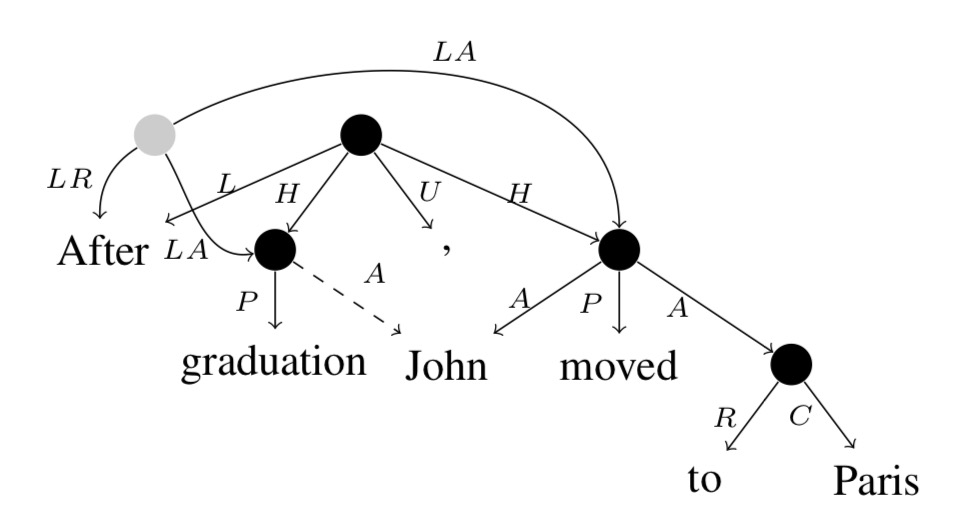
要还原成UCCA图只需要逆向执行第一步中的步骤即可。根据规则可以还原discontinuity,但是remote边需要额外的模型来处理。如果span parser给出了正确答案,经过简单的处理可以得到如下图的一个例子。边A-remote就表示还有remote边指向同一个节点,所以需要设计一个分类模型来找出还有哪一个节点指向该节点。问题的关键是如何表征一个node,假设对于图中的每一个node都有一个向量表示,我们就可以用bilinear或者biaffine实现多元分类。(新增:排除图中红色的节点,不可能作为remote edge的parent)
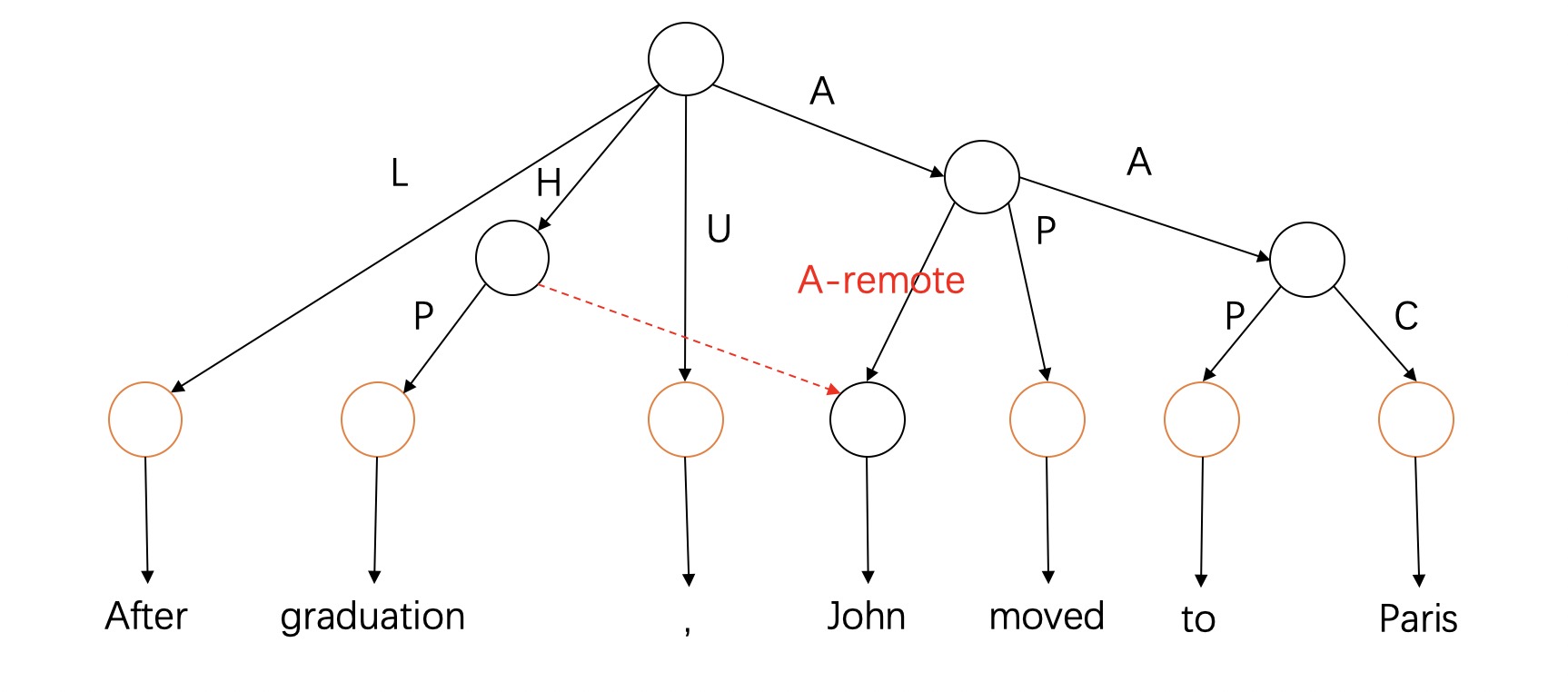
每个node都对应了一个span和指向它的label,所以可以借鉴span parser中的方法用向量表示node,然后用MLP-Biaffine或者Bilinear实现一个多元分类模型。