参考链接
下载与编译
GIZA++下载地址:github
fast align下载地址:github
进入GIZA++的主目录,执行make命令编译出可致执行文件。fast align的使用方法参考github上的README。
用GIZA++训练word alignment
准备好源语言以及目标语言的语料文件。文件每行一个句子,一行中词与词用空格隔开。
- 首先执行如下命令:
./GIZA++-v2/plain2snt.out toy.ch toy.en此时会生成四个文件:
toy.ch.vcb : 对应源语言的词典 toy.en.vcb : 对应目标语言的词典 toy.ch_toy.en.snt : 两个snt是对词进行编号后表示的句子,每个句对对应snt文件中的三行,第一行是该句对出现的次数,下面两行是编码后的句子,两个snt不同之处在于一个句对的上下顺序颠倒,这取决于对齐方向,ch在前 toy.en_toy.ch.snt : 两个snt是对词进行编号后表示的句子,每个句对对应snt文件中的三行,第一行是该句对出现的次数,下面两行是编码后的句子,两个snt不同之处在于一个句对的上下顺序颠倒,这取决于对齐方向,en在前 - 执行如下命令:
./GIZA++-v2/snt2cooc.out toy.ch.vcb toy.en.vcb toy.ch_toy.en.snt > toy_ch_en.cooc生成共现文件,文件内容是所有的共现词对,第一列是源端词id,第二列是目标端词id。
- 运行训练脚本:
nohup ./GIZA++-v2/GIZA++ -S toy.ch.vcb -T toy.en.vcb -C toy.ch_toy.en.snt -p0 0.98 -o toy -CoocurrenceFile toy_ch_en.cooc > toy.log 2>&1几个关键的参数: -S表示源端词表,-T表示目标端词表,-C是源端对应目标端的句子id,这三个文件都是在第一步中生成。 -o表示输出文件名的前缀,-CoocurrenceFile第二步生成的共现文件 完成后会生成许多文件,各个文件的含义请参考第一节中的博客链接。我们需要的文件是toy.A3.final:
# Sentence pair (4) source length 3 target length 4 alignment score : 0.0236746 I like smart phones NULL ({ }) 我 ({ 1 }) 喜欢 ({ 2 }) 手机 ({ 3 4 }) # Sentence pair (5) source length 1 target length 2 alignment score : 0.113485 smart phones NULL ({ }) 手机 ({ 1 2 }) - 训练一个反向的alignment
重新执行第二步和第三步,注意把某些参数顺序调换以及选择参数。
./GIZA++-v2/snt2cooc.out toy.en.vcb toy.ch.vcb toy.en_toy.ch.snt > toy_en_ch.cooc nohup ./GIZA++-v2/GIZA++ -S toy.en.vcb -T toy.ch.vcb -C toy.en_toy.ch.snt -p0 0.98 -o toy.rev -CoocurrenceFile toy_en_ch.cooc > toy.log.rev 2>&1同样我们得到alignment文件:toy.rev.A3.final。
对称化
下面使用fast align的一个脚本实现两端对称化。 所需脚本链接 : extract.py
- 运行脚本提取A3.final文件中的对齐信息:
python extract.py -i toy.A3.final -o toy.A3.final.extract python extract.py -i toy.rev.A3.final -o toy.rev.A3.final.extract -r输出文件的格式如下:
0-0 1-1 2-2 0-0 1-1 2-2 2-3 0-0 1-1 2-3 2-4 0-0 1-1 2-2 2-3 0-0 0-1请注意 加了-r之后会颠倒一下顺序。两个输出的文件,都是中文在左,英文在右。必须统一。
- 对称化
进入fast align的主目录,并编译好。
运行如下命令:
./atools -i toy.A3.final.extract -j toy.rev.A3.final.extract -c grow-diag-final-and > final_alignment.out得到最终的对齐文件,中文在左,英文在右。
可视化
所需脚本链接 : vision.py 运行命令:
python vision.py -s toy.ch -t toy.en -n 3
-n代表第几个句子,显示结果如下:
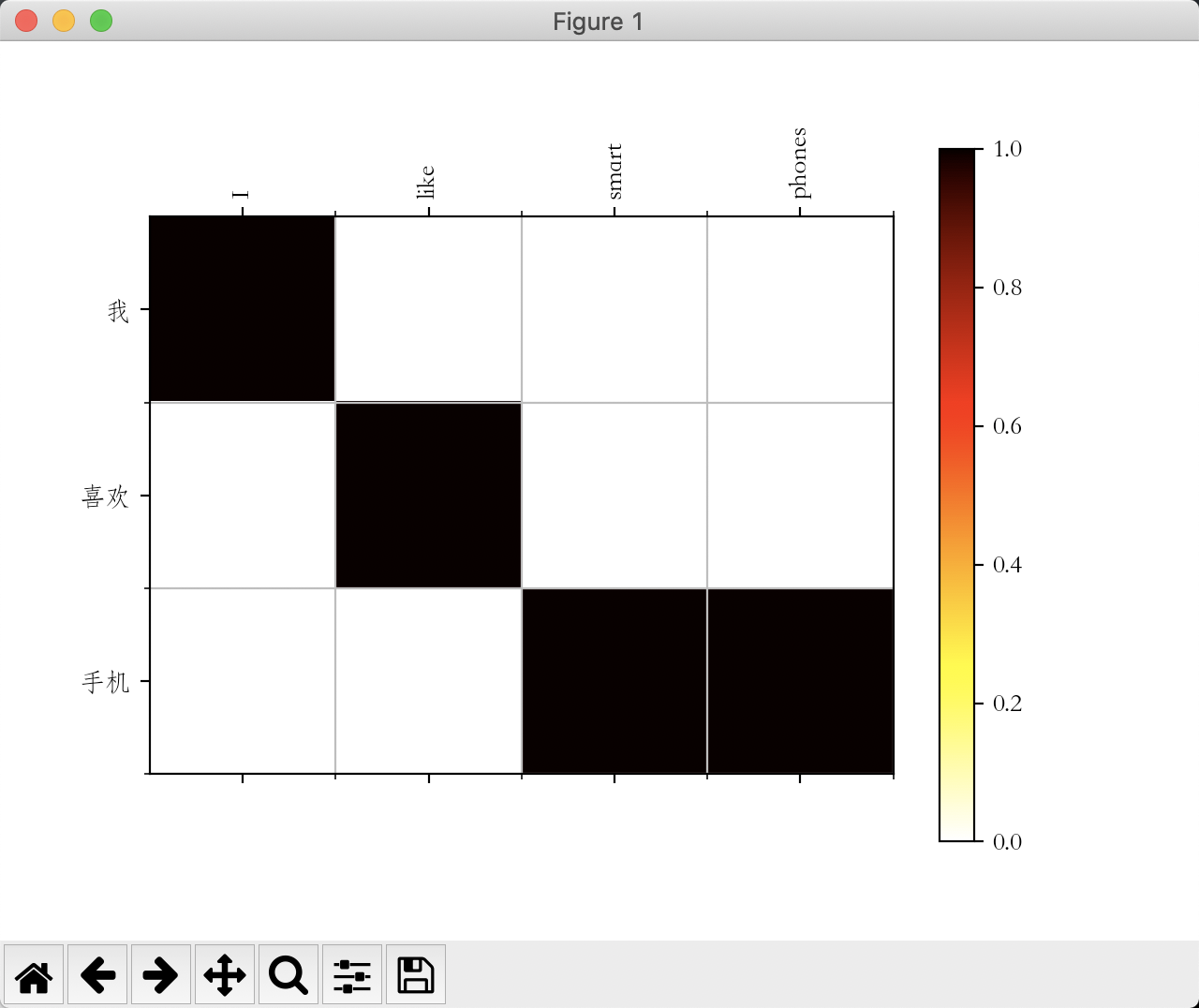 如果中文无法正常显示,请自行查找“matplotlib如何显示中文”,以后可能有空添加解决方案;请注意58-60行的注释。
如果中文无法正常显示,请自行查找“matplotlib如何显示中文”,以后可能有空添加解决方案;请注意58-60行的注释。