用短语结构句法分析来做UCCA
TODO
依存句法增强的UCCA
TODO
依存句法增强的NMT
相关工作
SMT相关:TODO
最早的NMT模型往往是end-to-end的,这也是其优点之一。鉴于SMT中句法的良好表现,研究人员尝试在NMT中加入句法来提高翻译质量。尝试将相关工作分成三类:显试地加入句法、隐式地加入句法以及MTL。
显式地加入句法意味着已经拥有了源端句子的句法树,如何将该句法树信息融入到NMT模型中是关键。较早时期,Sennrich et al.(2016) 尝试用语言学特征来改进NMT,这些特征就包括了句法树中的词性标签、关系标签等。将它们映射到一个稠密向量后和词向量一起输入到encoder端。显然这样做丢失了句法树的全局结构信息,那么如何完整地编码整棵树又成为了研究热点。较为简单的方法是按照规则线性化一棵句法树再用RNN进行编码(Li et al. 2017; Currey and Heafield 2018; Wu et al. 2018)。而更常用的方法是使用Tree-RNN(Eriguchi et al. 2016; Chen et al. 2017),这是一种专门为编码树状结构而设计的神经网络,往往比直接使用标签特征更有效。随着图神经网络的发展,也有工作尝试了用GNN作为句法树的编码器(Bastings et al. 2017; Beck et al. 2018),均取得了不错的效果。Hao et al. (2019)则是在transformer的MHA模型中融入了短语结构树的granularity信息。
由于源端的句法树通常是自动生成的,树的准确率就难以保证。这就带来了不可避免的错误传播问题。Zhang et al. (2019)提出了隐式的方法来融入句法信息。即将源端句子输入到句法分析器后,将句法分析器的编码器输出作为NMT源端的额外输入,而非最终生成的句法树。这些基于上下文的向量含有隐式的句法信息,而且可以减轻错误传播的影响。
MTL也是句法增强的一种有效办法,让NMT模型同时去学习句法,在翻译时也就能更注重句法的信息。Luong et al. (2016)、 Aharoni and Goldberg (2017)都是将短语结构树转换为string后与翻译任务同时学习。Wu et al. (2017)、Kiperwasser and Ballesteros (2018)、Pham et al. (2019)则是将依存句法分析转化为额外的序列生成任务。此外,Pham et al. (2019)还提出了一种用MHA来MTL依存关系的方法。
(会陆续增加一些新看的)
工作
Transformer baseline介绍:TODO。
Dependency parsing as an auxiliary task: 过去也有许多工作尝试将NMT与句法放在MTL框架下联合学习,但是它们大都是将短语句法或者依存句法分析看做一个序列生成任务,利用一个和NMT中一样的decoder来生成目标。这样做一个明显的缺点是训练速度较慢,尤其是在RNN框架下,生成序列的时间代价比transformer大很多。同时将句法分析建模成序列生成任务还可能会导致失去本身的结构化信息。随着基于图的句法分析方法的兴起,直接将依存句法分析作为图解析任务。具体来说就是用编码器得到每个词的表示,然后为每个词之间的边打上分值,最终从全连接的图中解码出一棵分值最大树。计算公式如下:TODO。
Joint parsing and MT model:基于图的依存句法模型同样可以看成一个encoder-decoder模型,区别在于该decoder并非传统的语言模型。下面介绍两种不同的MTL模型。
Share-equal:这是最常用也是最简单的MTL框架。在该框架下,机器翻译与句法分析模型共享相同的embedding以及编码器,不同的解码器用于不同的任务。这种模型下,两个任务平等的处于同一级别上,彼此交互,能充分学习到两者的共性。最重要的是对于机器翻译来说我们希望编码器能充分学习到源端句子的句法信息,从而帮助解码。
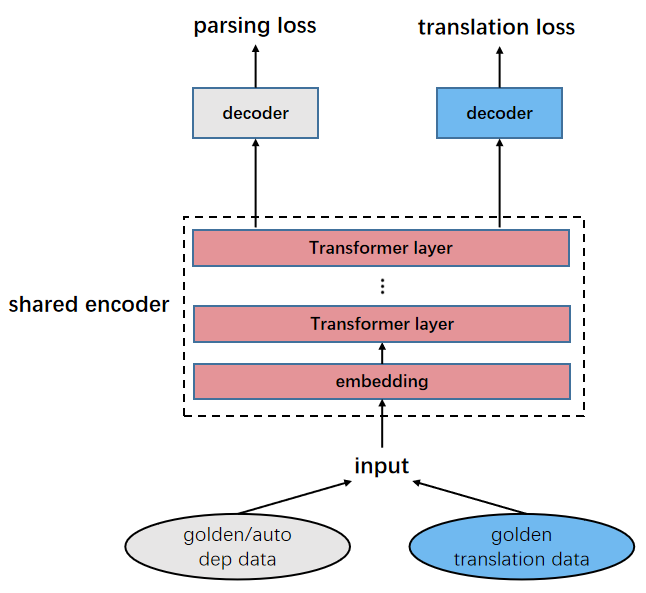
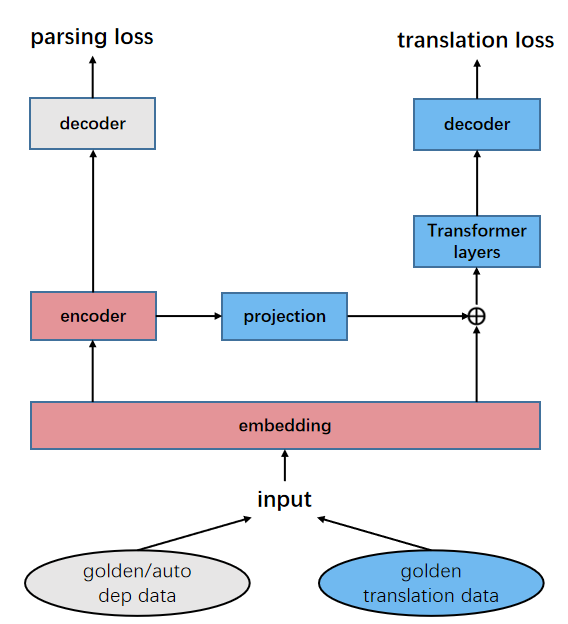
Stack-hidden:该模型下,我们使用两个独立的编码器来编码共享的embedding。对于依存句法分析来说和普通biaffine parser没有任何区别(这里的encoder还是选择LSTM而非transformer)。而对于机器翻译来说,我们先将embedding输入到依存句法的encoder中获取每一层的隐藏表示,将其作为额外的特征输入到NMT的encoder中。在该框架下,我们可以看做句法任务比机器翻译任务处在更低的级别上。
实验设置
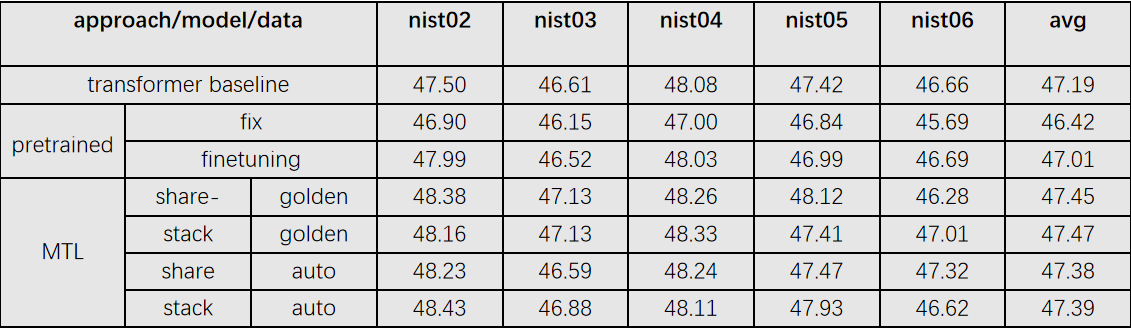
实验设置:我们在中-英 LDC数据集上进行实验,总共包含大约1.25M个句子对。我们取nist02数据集作为开发集,包含了878个句子。取nist03、nist04、nist05、nist06作为测试集,各包含了919、1788、1082、1664个句子。我们使用结巴工具对源端中文句子进行分词,并且使用BPE技术。目标端同样也用BPE技术,合并次数都设置为32K。我们基于开源的fairseq框架实现代码,transformer模型采用默认设置,batch大小设置为15000个token。对于share-equal模型,根据实验结果比较我们只共享encoder的前两层。对于stack模型我们采用和常规biaffine parser一样的设置,使用BiLSTM编码器,三层,维度为400。
源端句法数据:为了得到源端句法数据,我们使用在CODT上训练的biaffine parser来产生源端的自动句法树,同时我们把概率低于0.8的弧全部舍弃掉。除此之外,我们还尝试使用额外的标注句法数据,包括四种不同的规范,大约40w句。 为了保证和BPE之后的词一一对应,我们按照规则处理原始的句法树,具体来说一个词如果被切分成了多个subword,规定最右边的subword代表原来的核心词,继承原始的出边和入边。subword内部规定自右向左的弧,标签为额外添加的“subword”。
分析
使用句法的不同方法:Zhang et al (2019), LISA方法比较。
源端句法质量比较(auto、gold、auto+bert)。stack模型为例。
源端数据量比较(1/8、1/4、1/2)。
MTL句法性能比较。收敛速度比较。
标注数据。
存疑
换成RNN是否会更有效?transformer提取特征能力强,SA机制本身和依存词对关系类似,NMT上效果差别较大。换成RNN应该更能体现句法作用。
BPE的句法是否有影响?从句法的性能上来看应该没有影响。
显式句法?